On our open benchmark, running the identical model as Claude Code (Claude Haiku 4.5), Adsum fixed 4× more firmware bugs on the first device flash, at 3.8× fewer tokens on average and up to 13× on individual tasks. Anyone can rerun it.A clean architecture is only useful if it produces measurably better outcomes. Standard software benchmarks do not exercise hardware-in-the-loop work, and there is no established public benchmark for AI agents on embedded IoT firmware. We adapted methodology from research on expert-skill-augmented LLM evaluation for embedded code generation (arXiv:2603.19583) and built one, published open source as a deliverable equal in importance to the tool itself.
Setup
IoT-FirmwareDebugBench v0.1 runs on real nRF52840 DK and nRF52832 DK boards with NCS v3.2.1 (Zephyr 4.2.99). Six BLE-focused tasks across three difficulty levels, each with a precisely injected bug, a defined reproduction procedure, and a known correct fix. The most important choice: both agents run the same model, Claude Haiku 4.5, with reasoning disabled and prompt caching enabled identically. This isolates a single variable, the domain architecture. If Adsum IoT Coder outperforms, it is not because it has a more capable model; it is because the architecture wraps the same model differently. Difficulty levels. L1: root cause readable directly from logs. L2: requires inference from BLE behavior or Kconfig dependencies. L3: requires correlating state across two devices or full session timelines.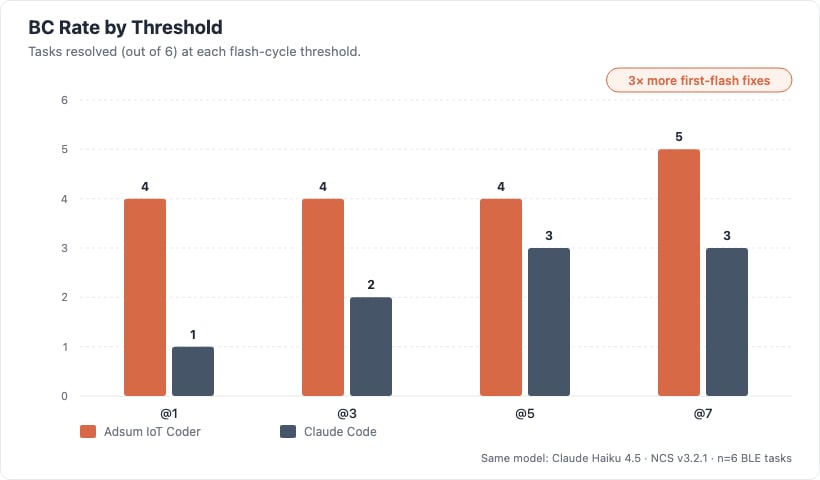
Bug-closed rate by flash threshold (BC@k = bug closed within k flashes).
Results
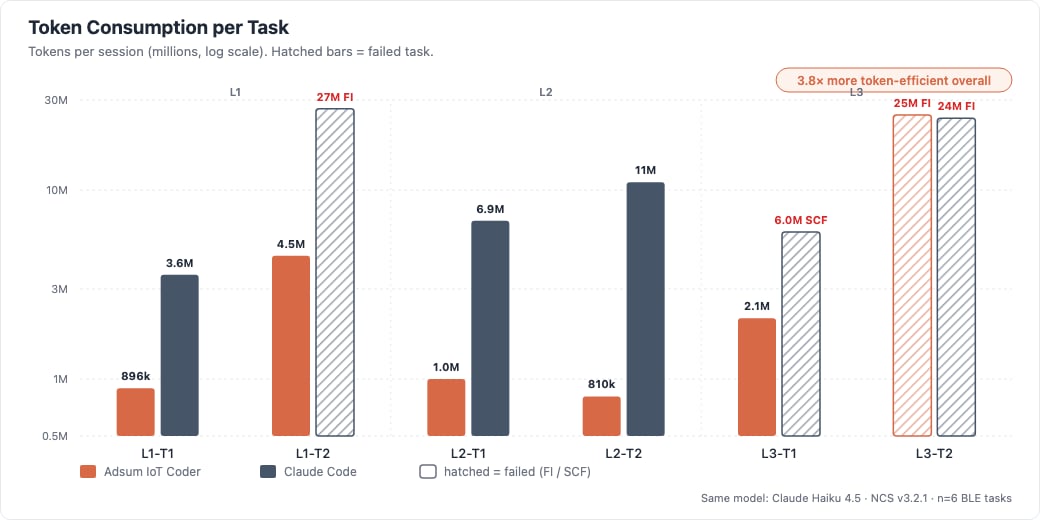
Token consumption per task: same model, different architecture.
What the gap shows
- Static Code Fix as a failure mode. Claude Code skipped log capture on two tasks and diagnosed from source alone. The dynamic skill architecture eliminates this by design: log capture is a first-class step in the loaded workflow, not an optional one the agent might skip under pressure.
- Context degradation predicted failure. On one task the baseline burned 27M tokens and lost the original symptom by the later debug cycles; Adsum resolved it at a 148.7k-token peak.
- The gap widens with difficulty. Parity at L2, Adsum 1/2 vs 0/2 at L3.
Full benchmark report
Per-task breakdown, honest limitations, and how to run it yourself.